PagerDuty vs Opsgenie in 2026 (And Is Better Stack Worth Considering?)
A side-by-side breakdown of two established incident management platforms — plus a look at whether a newer unified alternative deserves a spot in your evaluation.
The case for looking beyond the obvious two
PagerDuty and Opsgenie are the default names that come up in any conversation about incident management. Both are mature, well-documented, and trusted by engineering teams at scale. But "established" isn't the same as "best fit," and a third option has emerged that's worth putting on the shortlist alongside them.
Better Stack (formerly Better Uptime) is the first platform to genuinely unify three things that most teams currently piece together with separate tools:
- Incident management — on-call scheduling, alerting, and escalation policies
- Uptime monitoring — automated availability checks for websites, APIs, and services
- Status pages — built-in incident communication pages, no third-party integration required
For teams paying separately for PagerDuty and Pingdom, or Opsgenie and Uptime Robot, the consolidation argument is real. That said, this guide focuses primarily on the PagerDuty vs. Opsgenie comparison — Better Stack is an alternative worth knowing about, not a replacement for doing your homework on the incumbents.
Full disclosure: Better Stack is a commercial product. The comparison below draws on third-party review data and documented feature sets rather than first-party claims alone.
What third-party reviews say
On G2, Better Stack scores higher in user satisfaction than both PagerDuty and Opsgenie across reviews from software engineers, CTOs, and independent developers. This isn't decisive — G2 ratings reflect reviewer demographics and use cases, not absolute quality — but it's a useful data point when evaluating newer entrants against entrenched platforms.
Three things Better Stack does that neither PagerDuty nor Opsgenie offer
1. Native uptime monitoring
Rather than requiring an integration with Datadog, New Relic, Pingdom, or another third-party monitoring tool to trigger incidents, Better Stack includes its own monitoring engine. You can set up a monitor in under a minute to check:
- Website and service availability (uptime)
- Presence or absence of a specific keyword in a response
- Any IP address via ping
- APIs for correct response codes and payloads
- TCP/UDP port availability
- DNS server configuration
When an incident fires, the alert automatically includes debugging data from the monitor — screenshots, HTTP response codes, and a full incident timeline — without any additional integration setup.
2. Zero-integration incident workflows
Because monitoring is built in, a fully functional on-call alerting and incident management workflow can be configured without connecting a single external tool. The four core alerting channels — automated phone call, SMS, email, and mobile push notification — are available natively. Slack and Microsoft Teams can be added in a few minutes if needed.
For smaller teams or those just getting started with structured on-call, the absence of mandatory integration work is a meaningful time saving.
3. Built-in status pages
Status pages in Better Stack are native to the platform and connected directly to your monitors. Updating a service status takes one click, or it can be set to update automatically based on monitor state. Post-mortems and status reports can be published from the same interface used for incident management — no separate Statuspage.io subscription required.
PagerDuty vs. Opsgenie: a direct comparison
When evaluating incident management tools, four areas matter most: on-call scheduling, alerting, incident lifecycle management, and integrations. Here's how the two platforms compare across each.
1. On-call scheduling — advantage: Opsgenie
Opsgenie's scheduling interface is well-structured and easy to read. The dashboard surfaces the primary rotation, any active overrides, and the final computed schedule in a single view. A calendar/timeline toggle lets you see coverage patterns at different levels of granularity.
PagerDuty's scheduling page covers the same ground but is harder to navigate in practice. The timezone picker is a recurring pain point for distributed teams — it's not immediately clear how schedule entries will appear to engineers in different time zones, which creates coordination overhead.
Winner: Opsgenie, for cleaner scheduling UX and better at-a-glance readability.
2. Alerting — roughly equal
Both platforms support phone calls, SMS, email, Slack, Microsoft Teams, and mobile push notifications. The available channels on any given plan depend on pricing tier rather than platform capability.
Opsgenie's escalation configuration is the weaker point here. The settings are buried in the Teams menu, and building a multi-step escalation that combines phone, email, and Slack channels requires more navigation than it should. The lack of clear labeling makes it harder for engineers new to the platform to get it right without trial and error.
PagerDuty's escalation UX is more intuitive. Labels and descriptions explain what each option does, which matters when you're onboarding a new team member or modifying a policy during an active incident. The copy is clearer, and the logical flow of configuration steps is easier to follow.
Result: Draw, with PagerDuty having a slight edge in escalation usability and Opsgenie offering comparable raw channel coverage.
3. Incident lifecycle — advantage: PagerDuty
Opsgenie's incident view is clean and includes a useful timeline. Each resolved incident links to a basic post-mortem template, which is a practical touch. However, adding collaborators mid-incident is unintuitive, and there's no way to add inline notes or comments to an active incident — a meaningful gap when multiple engineers are working a problem simultaneously.
PagerDuty handles the incident lifecycle more completely. Adding responders, escalating to other teams, and leaving notes on active incidents are all straightforward operations. The collaboration model within an incident is clearly designed for multi-person response scenarios, not just individual acknowledgment and resolution.
Winner: PagerDuty, for more complete incident collaboration and a more natural multi-responder workflow.
4. Integrations — both are strong
Both platforms offer extensive integration libraries covering monitoring tools, ChatOps platforms, ticketing systems, ITSM tools, and more. The available coverage is broad enough to satisfy most engineering teams regardless of stack.
Opsgenie has a specific advantage for Atlassian shops. Jira, Trello, Confluence, and other Atlassian products integrate within a few clicks, and teams can use a single login across the Atlassian suite. If your organization already runs on Atlassian tooling, this reduces friction meaningfully.
Result: Draw, with Opsgenie pulling ahead for Atlassian-heavy environments.
Pricing: what to watch out for
Pricing is often the deciding factor — and both PagerDuty and Opsgenie have reputations for being more complex to evaluate than their list prices suggest.
A few things worth understanding before committing:
Add-ons can significantly increase the effective price. Both platforms offer features — certain alert channels, advanced analytics, specific integrations — as paid add-ons rather than including them in base tiers. Depending on your setup, these can meaningfully inflate the total cost compared to the headline per-user price.
Annual commitments reduce flexibility. Both platforms push teams toward annual contracts for better pricing. Before signing, be clear on what happens if your team size or needs change mid-term.
Enterprise sales tactics are a known issue. Public discussions on Reddit and other engineering communities include specific accounts of aggressive sales practices from both vendors around renewal and enterprise tier negotiations. If you're evaluating an enterprise plan, it's worth reading through community threads on this before entering a sales process.
Summary scorecard
| Category | PagerDuty | Opsgenie | Fluidify Regen |
|---|---|---|---|
| On-call scheduling UX | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Alerting channels | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Escalation setup | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| Incident collaboration | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| Integration breadth | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| AI post-mortems | ✗ | ✗ | ✓ |
| Self-hosted | ✗ | ✗ | ✓ |
| SSO free | ✗ | ✗ | ✓ |
| Free tier | ✗ | ✓ (up to 5 users) | ✓ (unlimited, AGPLv3) |
| Pricing predictability | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
How to decide
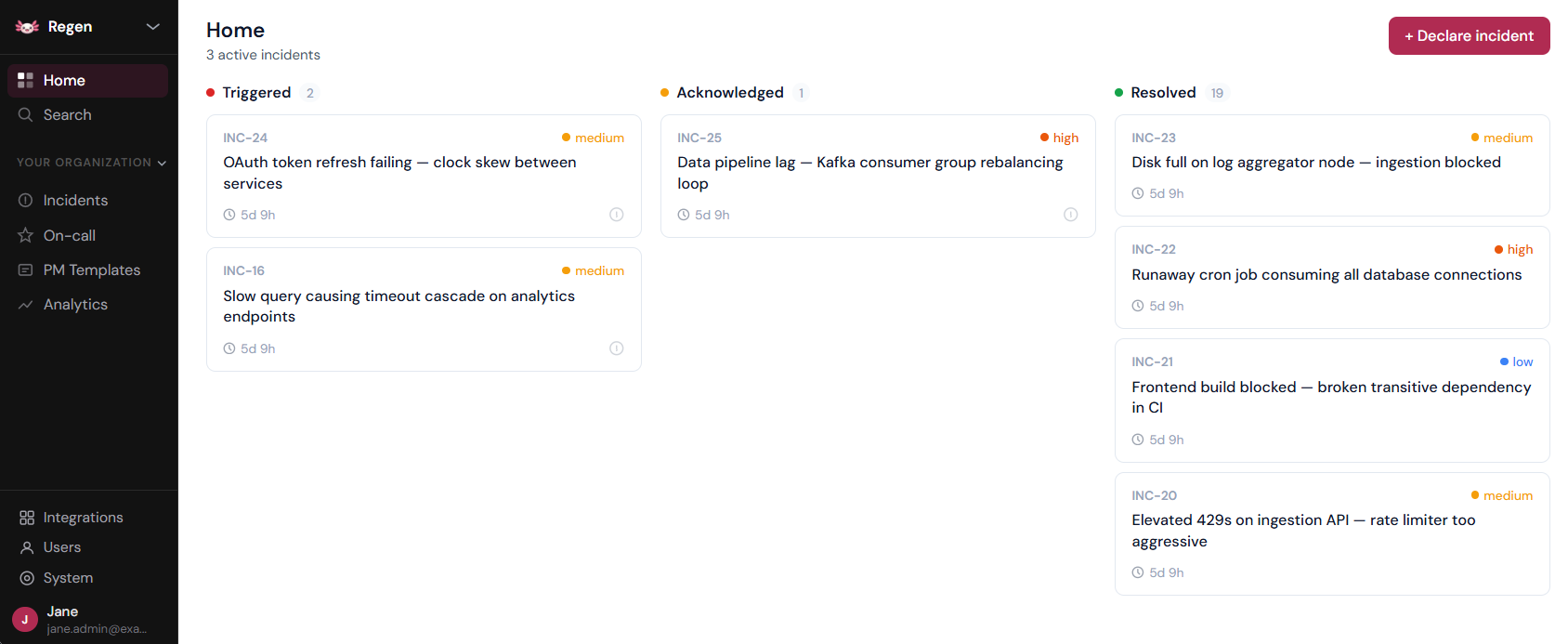
Choose PagerDuty if your team needs the most complete incident lifecycle tooling available and is willing to pay for it — and if you're already running an external monitoring solution you're happy with.
Choose Opsgenie if your organization runs on Atlassian tooling, you want a more accessible free tier to get started, or you need clean on-call scheduling without PagerDuty's complexity. Opsgenie's price-to-feature ratio at the mid-tier is generally stronger.
Consider Fluidify Regen if you're paying $30–50 per user for PagerDuty or incident.io, operating in a regulated industry where incident data can't leave your infrastructure, or were running Grafana OnCall before the March 2026 archival and need a self-hosted replacement with a real migration path. It trades managed SaaS convenience for full data ownership, no per-user pricing, and a codebase you can actually audit.
Final thoughts
There's no objectively correct answer between PagerDuty and Opsgenie. Both are capable platforms with real trade-offs.
Opsgenie edges ahead on scheduling clarity and is the stronger choice for Atlassian-integrated teams. PagerDuty handles the full incident lifecycle better and has a more polished escalation configuration experience.
The more useful question for most teams isn't which of these two is better — it's whether either of them is actually the right tool for where your team is today. If you're still stitching together incident management with a separate monitoring tool and a separate status page, a platform that handles all three might be worth the evaluation time.