Top 10 Incident.io Competitors for 2026
Incidents make any on-call engineer go anxious for a second. Within the realm of system observability, that anxiety multiplies if you lack a structured framework for triaging incoming crises.
This necessity has fueled the rise of specialized management platforms, positioning Incident.io as a prominent choice for many DevOps organizations. However, is it a universal fix? Not quite. Despite its strengths, many teams find themselves scouting for alternatives that better align with their specific budgets or technical requirements.
Below, we analyze the 10 premier alternatives available in 2026. First, let’s briefly frame what Incident.io brings to the table.
Incident.io: Core Functionality
Incident.io distinguishes itself by focusing exclusively on the incident lifecycle. It avoids feature bloat by centering its utility on four pillars:
- Shift Coordination: Organizing on-call rotations.
- Direct Response: Handling outages in real-time.
- Communication: Managing external and internal status updates.
- Retrospectives: Generating post-incident learnings.
While efficient, its Slack-centric approach and specific pricing model don't always fit every architectural philosophy.
Incident.io: Investment Costs
The platform operates on a tiered system starting with a Team plan at $15 per user/month, plus a $10 monthly surcharge for every on-call participant. The Pro tier jumps to $25 per user/month, with on-call participants costing an extra $20 each, though it adds AI-assisted analysis and deeper metrics. Enterprise-level needs require a bespoke quote.
The Leading 10 Incident.io Alternatives in 2026
1. Fluidify Regen
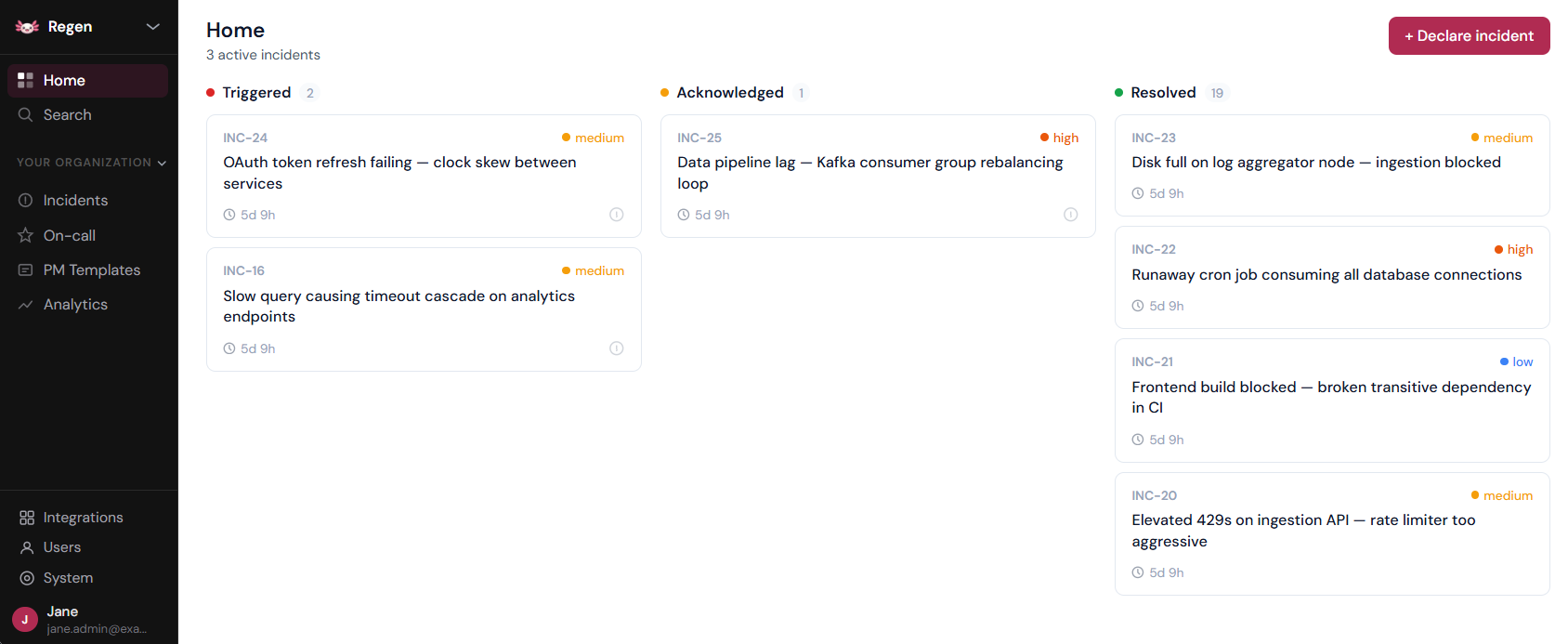
Fluidify Regen is an open-source incident management platform that replaces your fragmented alerting and incident stack with a single self-hosted system. It's what you get when you combine PagerDuty's alerting, incident.io's coordination, and AI-powered post-mortems — without the $100k/year price tag or vendor lock-in.
🌟 Core Capabilities
- Alert ingestion from any monitoring tool (Prometheus, Grafana, CloudWatch, generic webhooks)
- Immutable incident timelines with automatic Slack/Teams integration
- AI-generated post-mortems from actual incident data (bring your own API key)
- On-call scheduling with layer-based rotations and escalation policies
➕ Why Teams Choose Regen
- Data sovereignty: Self-hosted, your incidents never leave your infrastructure
- No SSO paywall: SAML included in the free tier (we're anti-sso.tax)
- Drop-in Grafana OnCall replacement with one-click migration
- Open core model: AGPLv3 community edition is feature-complete
➖ What It's Not
- Not a monitoring tool (integrates with your existing observability stack)
- Not a SaaS offering (self-hosted only, by design)
💲 Pricing
Community (AGPLv3): Free, unlimited users, includes SSO/SAML
Enterprise: Contact for SCIM provisioning, audit log export, RBAC, retention policies
🔗 Get Startedgithub.com/FluidifyAI/Regen — Deploy in under 5 minutes with Docker Compose or Kubernetes.
2. BigPanda
BigPanda leverages automation to help IT departments manage system health in real-time. Its "Incident 360 Console" acts as a central nervous system, offering a unified perspective on all active troubles to facilitate cross-departmental root cause analysis.
🌟 Primary Capabilities
- Alert and incident intelligence
- Automated workflow triggers
- Consolidated analytical dashboards
➕ Advantages
- Utilizes machine learning to correlate related alerts.
- Highly flexible API for custom data ingestion.
➖ Limitations
- Lack of transparent online pricing.
- Minimal recent public user documentation.
💲 Pricing Financial details are restricted to private sales consultations.
3. LogicMonitor
LogicMonitor is a heavyweight in infrastructure tracking that includes native incident handling. It manages to provide enterprise-grade complexity without the typical headache of manual configuration. Its agentless "LM Envision" platform automatically maps out server health and SQL performance.
🌟 Primary Capabilities
- Cloud and infrastructure oversight
- Digital experience tracking
- Automated metric detection
➕ Advantages
- Highly modular and adaptable.
- Deep granularity in data harvesting.
➖ Limitations
- Significant price point for smaller teams.
- Some users find initial alert tuning to be complex.
💲 Pricing Starts at roughly $22 per resource per month, which can accumulate quickly in large-scale environments.
4. FireHydrant
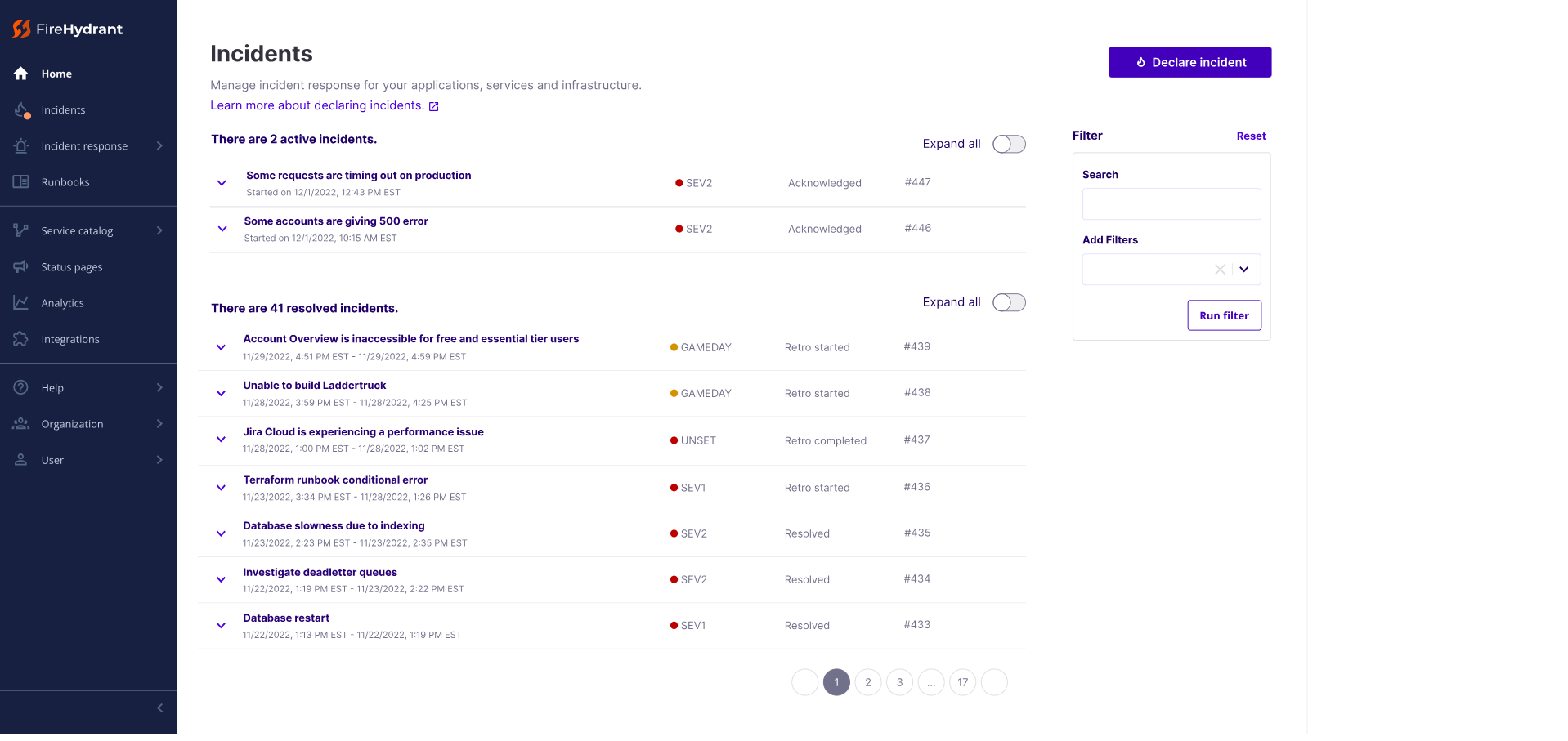
FireHydrant was built to standardize and automate the chaos of the incident lifecycle. It provides a guided experience, primarily through Slack, ensuring that rapidly growing engineering teams maintain high reliability standards.
🌟 Primary Capabilities
- Structured incident response workflows
- Automated task assignment and audit trails
➕ Advantages
- Excellent for ensuring process consistency.
- Highly customizable for specific team needs.
➖ Limitations
- The lack of a monthly payment option can be a barrier.
- Analytics features have historically been a point of user feedback for improvement.
💲 Pricing The standard Pro plan is billed annually at $6,000.
5. Opsgenie
Opsgenie is a veteran in the space, known for its reliability and centralized alert routing. It is particularly effective for teams already entrenched in the Atlassian ecosystem, offering sophisticated scheduling to ensure the right person is always notified.
🌟 Primary Capabilities
- Intelligent alert routing and scheduling
- Multi-channel notification logic
➕ Advantages
- Seamlessly bridges the gap between monitoring and ticketing (Jira).
- Flexible on-call rotations.
➖ Limitations
- Some advanced post-mortem features are locked behind high-tier plans.
💲 Pricing Free for up to 5 users. Paid tiers begin at $9 per user/month (Essentials) and scale to $29 for full Enterprise capabilities.
6. Sematext
Sematext treats incident management as a subset of its wider observability ecosystem. It allows teams to set specific thresholds across metrics and logs, facilitating a collaborative environment for resolving failures as they happen.
🌟 Primary Capabilities
- Real-user and synthetic monitoring
- Log analytics and incident timelines
➕ Advantages
- Extensive integration library (100+).
- Automated host and container discovery.
➖ Limitations
- Dashboard configuration can feel overly technical.
- Log retention costs can scale rapidly.
💲 Pricing Infrastructure monitoring starts as low as $3.60 per host, with various tiers based on data retention needs.
7. xMatters
xMatters provides a stable, straightforward foundation for incident response. While it may not boast the cutting-edge AIOps of its peers, its strength lies in its simplicity and dependability for essential alerting and shift management.
🌟 Primary Capabilities
- Core incident management
- Simple workflow automation
➕ Advantages
- Highly reliable for standard notification needs.
- Lower complexity compared to full-stack platforms.
➖ Limitations
- Automation setup can be unintuitive.
- Batch-closing alerts can be time-consuming.
💲 Pricing Offers a free tier for small setups, with professional plans starting at $9 per user/month.
8. Squadcast
Squadcast is a strong direct competitor to Incident.io, focusing on SRE-driven workflows. It merges on-call management with reliability metrics like SLO tracking, providing a unified view of service health.
🌟 Primary Capabilities
- SRE and reliability workflows
- Public and private status pages
➕ Advantages
- Intelligent alert routing reduces "noise."
- Easy integration with Prometheus and Zabbix.
➖ Limitations
- Can be expensive for teams with many users.
- New users may face a steep initial learning curve.
💲 Pricing Free for 5 users; Pro plans start at $9 per user/month.
9. Moogsoft
Acquired by Dell, Moogsoft is an AIOps-first platform. It is designed to proactively identify issues before they impact users by using machine learning to find patterns in monitoring data.
🌟 Primary Capabilities
- AI-driven incident detection
- Cross-platform data ingestion
➕ Advantages
- Excellent at correlating disparate alerts into single incidents.
- Reduces manual triage time.
➖ Limitations
- Customization options can feel restricted.
- Limited public-facing reviews since its acquisition.
💲 Pricing Requires direct contact with the Dell sales team for custom quotes.
10. Better Stack
Better Stack offers a cohesive experience by weaving uptime monitoring and log management directly into the incident response fabric. It is designed to act as a watchful guardian over your infrastructure, providing rapid alerts the moment a critical event is detected.
The platform excels at distilling massive log volumes into actionable intelligence, triggering alarms when anomalies surface. Its robust integration library makes it a versatile hub for any DevOps stack.
🌟 Primary Capabilities
- End-to-end incident orchestration
- High-speed log aggregation and analysis
- Uptime and API health checks
- Centralized observability views
➕ Advantages
- Built-in transparency via status pages.
- Ultra-fast check intervals (every 30 seconds).
- Sophisticated on-call logic to prevent staff burnout.
➖ Limitations
- While broad, it doesn't aim to be a "heavy" full-stack observability suite like Datadog.
💲 Pricing Free versions exist for both monitoring and logging. Paid packages begin at $25 monthly, which expands monitoring capacity and integrates full incident management tools.
Comparison Summary
| Tool | Focus | Starting Cost |
|---|---|---|
| Fluidify Regen | AI Native Oncall Management | Free |
| BigPanda | ML Alert Correlation | Custom |
| LogicMonitor | Heavy Infra Monitoring | $22/resource/mo |
| FireHydrant | Process Standardization | $6,000/yr |
| Opsgenie | Integrated Alerting | $9/user/mo |
| Sematext | Full Observability Suite | $3.60/host |
| xMatters | Reliable Messaging | $9/user/mo |
| Squadcast | SRE-Focused Management | $9/user/mo |
| Moogsoft | AIOps Triage | Custom |
| Better Stack | Observability + Incident Response | $25/mo |
Final Word
If Incident.io doesn't feel like the right fit for your workflow, you aren't without options. Whether you need the predictive power of Fluidify Regen or the all-in-one observability of Better Stack, the 2026 market is diverse. I recommend testing a few of these in your specific staging environment to see which truly minimizes your team's "incident fear."